The Word2Vec algorithm is an unsupervised algorithm that takes a word as input and returns a vector which describes this word in a high dimension space (for example, 300-500 dimensions). Prior to Word2Vec, the most popular algorithm to convert words to vectors was the bag-of-words model, which simply indicates presence or absence of the word.
The weakness of Bag-of-words model was the vectors had a poor notion of distance. For example, the word vectors for Paris and France would have no apparent similarity in Bag-of-words, but Word2vec generates vectors that can not only tell that these words are similar, but can derive relationships which determine the capitals of other countries, given only the country names.
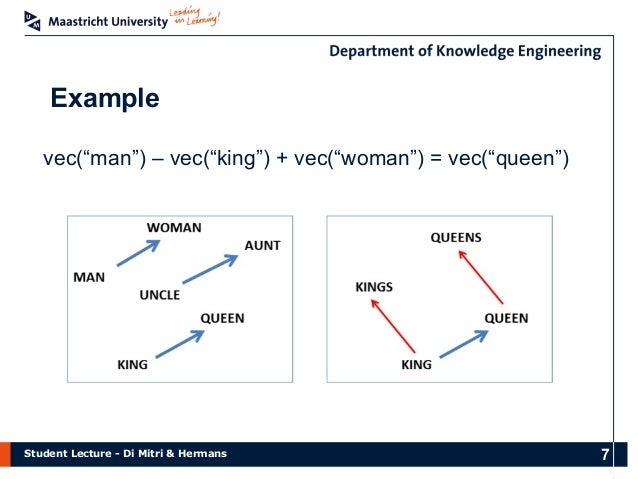 |
| Image courtesy Maastricht Uni, Dept of Knowledge Engineering |
I implemented a Clojure library that wraps a Java implementation of Word2Vec. More details (and a short tutorial) in this blog post (Crossposted from the Bridgei2i Github site)